October 2015
AlphaGo defeated European champion Fan Hui with 5-0.
AlphaGo is the first computer program to defeat a professional human Go player, the first to defeat a Go world champion, and is arguably the strongest Go player in history.
Go is known as the most challenging classical game for artificial intelligence because of its complexity. Despite decades of work, the strongest Go computer programs could only play at the level of human amateurs. Standard AI methods, which test all possible moves and positions using a search tree, can’t handle the sheer number of possible Go moves or evaluate the strength of each possible board position.
Go originated in China over 3,000 years ago. Winning this board game requires multiple layers of strategic thinking.
Two players, using either white or black stones, take turns placing their stones on a board. The goal is to surround and capture their opponent's stones or strategically create spaces of territory. Once all possible moves have been played, both the stones on the board and the empty points are tallied. The highest number wins.
As simple as the rules may seem, Go is profoundly complex. There are an astonishing 10 to the power of 170 possible board configurations - more than the number of atoms in the known universe. This makes the game of Go a googol times more complex than chess.

The Game of Go is the holy grail of artificial intelligence. Everything we've ever tried in AI failed when you try the game of Go.
I thought AlphaGo was merely a machine. But when I saw this move, I changed my mind. Surely, AlphaGo is creative.
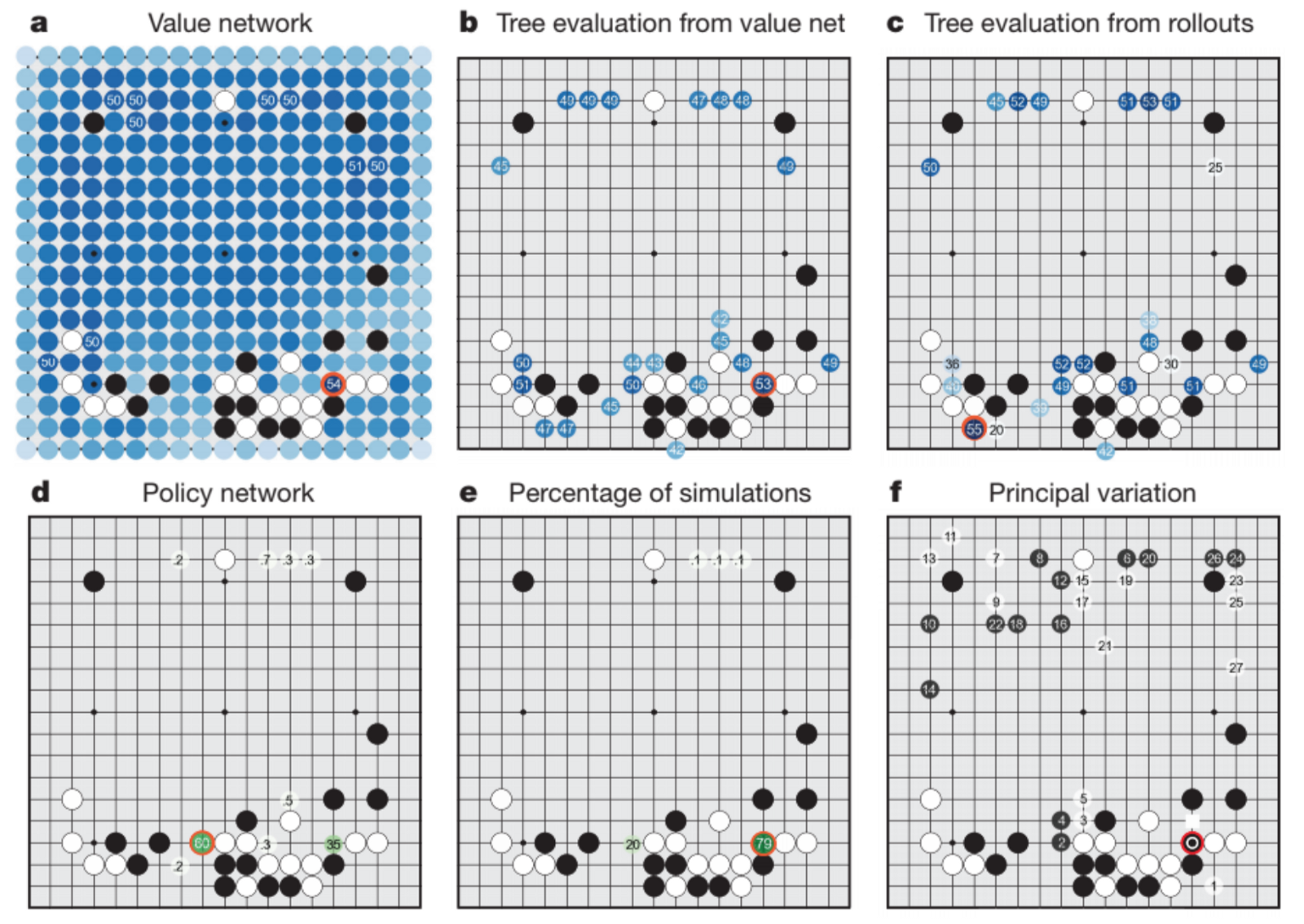
Google Deepmind created AlphaGo, a computer program that combines advanced search tree with deep neural networks. These neural networks take a description of the Go board as an input and process it through a number of different network layers containing millions of neuron-like connections.
One neural network, the “policy network”, selects the next move to play. The other neural network, the “value network”, predicts the winner of the game. We introduced AlphaGo to numerous amateur games to help it develop an understanding of reasonable human play. Then we had it play against different versions of itself thousands of times, each time learning from its mistakes.
Over time, AlphaGo improved and became increasingly stronger and better at learning and decision-making. This process is known as reinforcement learning. AlphaGo went on to defeat Go world champions in different global arenas and arguably became the greatest Go player of all time.
The typical, traditional, classical beliefs of how to play — I’ve come to question them a bit.
It's perfect, it's just flawless, merciless. ... I don't think I could catch up with it in my lifetime.
AlphaGo defeated European champion Fan Hui with 5-0.
AlphaGo defeated 18-times world champion Lee Sedol with 4-1.
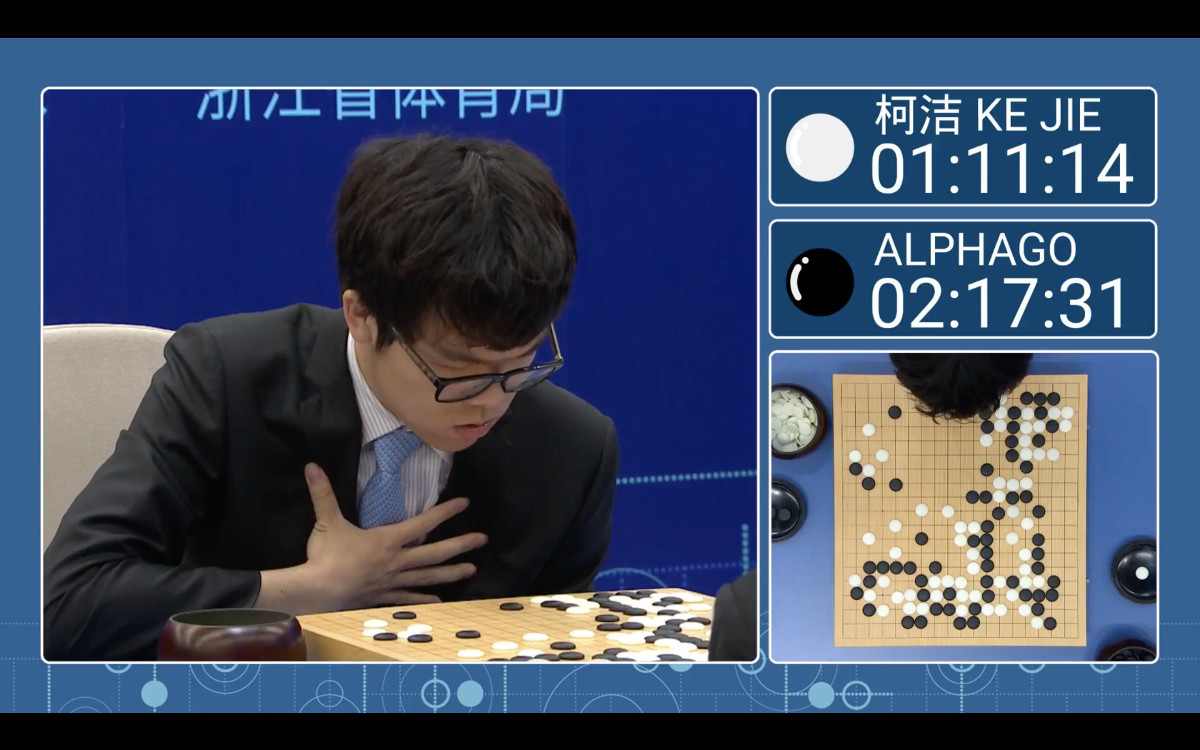
AlphaGo defeated world's first Go player Ke Jie with 3-0.
In October 2015, AlphaGo played its first match against the reigning three-time European Champion, Mr Fan Hui. AlphaGo won the first ever game against a Go professional with a score of 5-0.
AlphaGo then competed against legendary Go player Mr Lee Sedol, the winner of 18 world titles, who is widely considered the greatest player of the past decade. AlphaGo won a 4-1 victory in Seoul, South Korea, on March 2016.





In January 2017, Deepmind revealed an improved, online version of AlphaGo called Master. This online player achieved 60 straight wins in time-control games against top international players.
Four months later, AlphaGo took part in the Future of Go Summit in China and defeated Ke Jie, the world's first Go player at that time, 3-0.
Directed by Greg Kohs with an original score by Academy Award nominee, Hauschka, AlphaGo chronicles a journey from the halls of Cambridge, through the backstreets of Bordeaux, past the coding terminals of DeepMind in London, and, ultimately, to the seven-day tournament in Seoul.